こんにちは。こんばんは。 開発生産性の可視化・分析をサポートする Findy Team+ のフロントエンド リードをしている @shoota です。
Findy Team+はエンジニア組織の開発生産性を可視化し、開発チームやエンジニアリングメンバーのパフォーマンスを最大化するための支援をしています。 そして(当然のことながら)Findy Team+ を作っている自分たちも、チームや個人でドッグフーディングをして、チームや自分自身の働き方やエンジニアリング組織の健康チェックをしています。
今回はそんな Findy Team+の開発チームのうち、フロントエンドチームがどのような開発環境・開発インフラで働いているかの概要をご紹介したいと思います。
フロントエンド技術スタックとCI高速化
技術スタック
まずはじめにフロントエンドの技術スタックを簡単に紹介します。一般的なSPA構築の技術スタックを採用しており、それほど特別なものではないことをご理解いただけると思います。
- React
- TypeScript
- GraphQL
- Emotion
- Storybook
- Testing
- Linter / Formatter
ここまではいわゆる一般的なSPAの構成ですが、Findy のフロントエンドはモノレポ管理ツールである Nx を利用することで高速化を図っています。 Nxの機能詳細についての説明はここでは省略しますが、トップページに「Smart Monorepos・Fast CI」とある通り、CIの高速化が簡単に管理できるところが最大の特徴と恩恵だと思っています。
NxでCIを高速化する
Nxは内部に複数のプロジェクトを持つことができ、且つ、それらの依存関係を自動で解析します。 この「プロジェクトの依存関係」をもとに、プルリクエストでの「変更されたプロジェクト」と、その「変更部分が依存しているプロジェクト」のみのテストを実行する手段を提供しています。
これによって開発者が開発しているものに関係のない部分は省略されるためCIが高速化します。 それ以外の変更についてもNx Cloudにキャッシュが残っていればその結果を採用してテスト等をパスさせ、CIが高速に完了します。
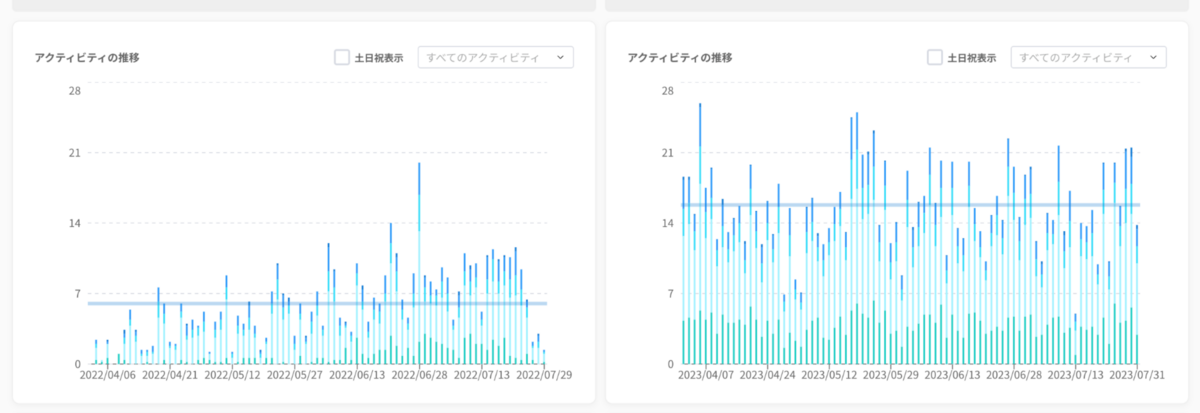
CIの実行結果を載せてみました。

また単にCIが高速化される以外にも、Nxは開発生産性の向上に寄与してくれます。 それは「プルリクエストはできるだけ小さく作ろう」という開発文化を「CI時間」という数値で可視化してくれることです。
前述の通りプルリクエストの変更の依存関係が小さいほどCIは早く終わりますので、逆にプルリクエストが広範な範囲で大きくなってしまうほどCI時間が長くなります。 プルリクエストの粒度が大きいと、1) CIが遅くなり、2) レビュー依頼するまでの時間が空いて忘れがちになり、3) レビュー量も多くて時間がかかるという悪循環に陥ります。
そこでプルリクエストを作る側はどうにかこれを避けようとする力学が働き、CIが高速であれば作業内容に集中し、レビュー指摘の反応や修正も楽になっていくのです。
プルリクエスト / レビューに反応する
前述の通りNxの依存管理を基盤としてCIを高速化していますが、Findy ではレビュー依頼やレビューコメントなどGitHubでのやり取りをSlackに移植してコミュニケーションのトリガーを通知しています。 実際のSlackの画面はお見せできませんが、以下のようなタイミングでSlackに状況が実況され、レビュー依頼が来た場合は通知もされます。
- プルリクエストを作った時
- プルリクエストにコメントされた時
- プルリクエストがApproveされた時
- プルリクエストをマージ(クローズ)した時
またGitHub標準のSlackアラート機能も併用していて、レビュワーにアサインされたままのプルリクエストがあれば1時間ごとに通知されます。 これによって「レビュー依頼に気づかなかった」状況を減らし、レビューが放置ぎみのときには「なにか事情があるのかな?作業に入れない状況かな?」と察したり、レビュワーを変更するなどの対処もできます。
このSlack Appは弊社テックリードのgithub-to-slack-notification をベースに構築されています。

プルリクエストを分類する
Findy Team+ は、開発メンバー、開発チーム、リポジトリ、プルリクエストのラベル、日時やカレンダー情報などの複数の条件をディメンションとして、個人やチームのリードタイムやアクション数などのパフォーマンスを計測できます。 プルリクエストは機能開発やリファクタリング、バグ修正、ドキュメンテーションなど内容が様々になってしまうため、パフォーマンスがどのような部分で発揮されているかを分類するのは非常に困難ですが、Team+ではプルリクエストのラベルを利用して一定の分類ができるようにしています。
しかし一方で、「プルリクエストにラベルをつけておく」という作業を定常的に、すべてのエンジニアが、漏れなく、間違いなく、実施していくのはプルリクエストの分類以上に困難なことでしょう。 Slackを見返すと入社3日目の自分がいきなり本質をついています。

Findy Team+のフロントエンドのプルリクエストは自動でラベルをつけています。
そもそもgit上の全てのコミットは Conventional Commits に則るよう、commit lint で制約を設けています。 そしてプルリクエストのタイトルもConventional Commitsの形式にするようにルール化しているので、プルリクエストのタイトルにはこれらの接頭句が必ずあり、これを検知してGitHub Actionsで分類、対応するものにラベルをつけるようにしてます。

デプロイする
小さなプルリクエストが無事にマージされたら、デプロイしていきます。Team+ フロントエンドは、GitHub Actionsの schedule cronを利用して一日に2回定期デプロイをしています。 gitはgit-flowをベースにした運用をしつつ、プルリクエストテンプレートにリリース時に必要な確認項目を入力する欄を設け、リリース時にはこの確認項目を自動生成するようになっています。 まずはgitの運用フローを簡単に図式化してみました。

developブランチを定時間でリリース用ブランチに派生して、ステージングにデプロイします。 このときの主なチェック項目として、
- バックエンドで先行するプルリクエストがないか(ある場合はそのプルリクエストのリンク)
- APIレスポンスの変化やエラーハンドリング、後方互換性など、開発者のみが確認できる確認項目がないか
- 実装機能と想定仕様の合致など、機能リリースのためのQAが必要でないか
をプルリクエストテンプレートで記載するようにしており、リリースプルリクエストにはこれらすべてを列挙して簡易的なリリース判定を行っています。
まとめ
今回は Findy Team+ の開発フローに焦点をあてていくつかの要素をご紹介しました。 これ以外にもさまざまなツールやサービスを利用して品質とスピードを両立させるための開発基盤を持っていますが、ひとことではお伝えしにくいものもあるので、それぞれより詳細な記事でご紹介して行ければと思います。
スピードを意識したフロントエンド領域の開発環境として高いレベルで整備し、可視化して改善するように心がけています。 自分の開発能力、スピードをフルに発揮したいという方は、ぜひ下の採用情報もごらんください。